
As language models become increasingly prevalent, there has a been a heavy effort in establishing tools for regulation and accountability of these models. The White House has even released preliminary efforts for the development and deployment of new tools. In this post, I want to provide some level of understanding for one of these approaches, called watermarking and more specifically watermarking for language models. My goal is to provide an easier to digest version of the current landscape of the approaches to watermarking, highlight some of the problems that come up with language model watermarking, and advocate for recent “cryptographic-style” approach to watermarking language models.
My own interest in this topic started about a year ago, when Aloni Cohen, Gabe Schoenbach, and I started a project about building better and more powerful language model watermarks and also unifying the literature into a common language. Recently, we posted a pre-print of our own contribution to this line of work in, a paper called Watermarking Language Models for Many Adaptive Users. In that work, we present a lot of the ideas below more formally and (painstakingly) detail out prior works can fit into our unified framework. Hopefully, this provides the same intuitive comparison of prior works without the difficult math.
If you already know what ChatGPT is, then congrats! You have a pretty good idea of what a language model is. At a high level, we’ll just think of a language model as some function which takes a prompt like, “write me a paragraph about a young wizard in the united kingdom”, and outputs some response that is modeled on natural language, for example (from ChatGPT-4o):
In the heart of the United Kingdom, young wizard Oliver Hale embarked on a journey that would change his life forever. Residing in a quaint cottage on the outskirts of a small village, Oliver discovered his magical lineage on his twelfth birthday. With a wand crafted from ancient oak and a heart full of curiosity, he began his education at the prestigious Pendragon Academy of Magic. Surrounded by rolling hills and mystical forests, Oliver honed his skills in spellcasting, potion-making, and magical creatures care. His adventures led him through enchanted woods, secret tunnels, and hidden chambers, unveiling the rich tapestry of Britain’s magical history. With every spell he mastered, Oliver grew closer to uncovering the secrets of his heritage, forging friendships and facing challenges that would shape him into a wizard of extraordinary potential.
This response and the prompt are made up of tokens, which are just small units (sometimes letters, words, or word fragments), that make up how the language model reads and writes its output. You can see these tokens in action using the OpenAI tokenizer tool, which can visualize and specify what the tokens are in a specific prompt or response. There can also be special “end of prompt” or “end of response” tokens that are usually hidden to the user.
For our watermarking breakdown, it will be helpful to understand a bit more of what’s going on inside this language model. Specifically, we’ll assume that the language model works as shown in the picture below. In the image, we’re just showing a bit more detail on how the model generates the response from the given prompt. In particular, given a prompt and a partial response (which starts out as empty), all a language model needs is a “next token?” distribution.
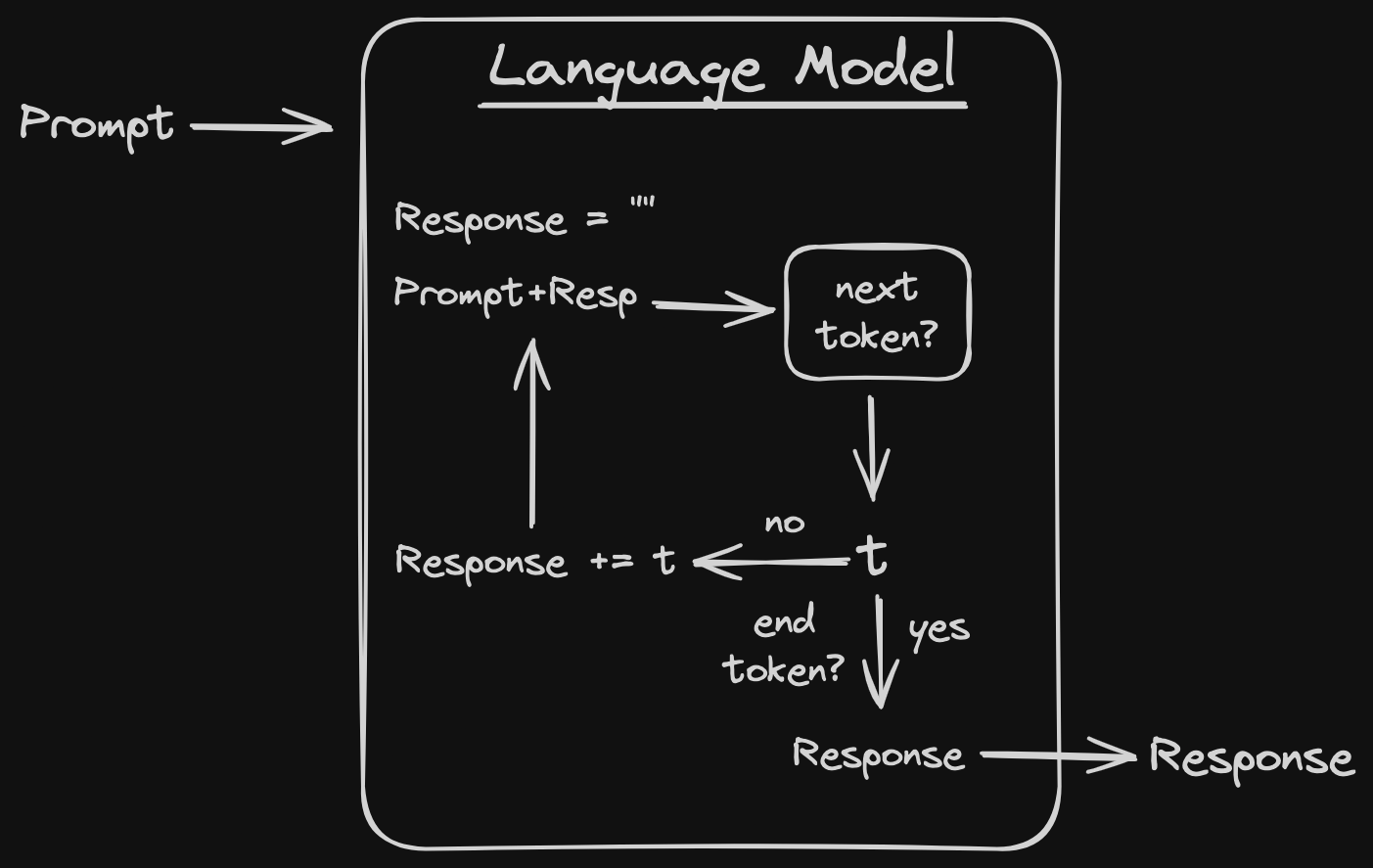
This abstraction captures how all major language models to date work (GPT, Llama, etc). Each as a different “next token?” distribution, which is based on all their training procedure. But, given a prompt and partial response, any of these models has some underlying specification of the distribution that the next token is drawn from. Generating a response from any of these models just amounts to running this loop until it terminates, sampling a token randomly each time.
It’s also worth noting that in this abstraction, the language model is sampling from the distribution for each token. However, this is done by specifying the distribution (probabilities for each token) exactly and then sampling. This means that (for current models), the distribution can be efficiently written down, which means it can be be used in other why by other sub routines.
Now that we know what a language model is, we need to make it clear what we want to do with it and what it means to watermark the language model outputs. People have developed watermarks for ages though, so we also need to appreciate the differences between watermarking a language model output compared to other things. Specifically, I’ll compare it to images, video, and audio, which have all be outputs of recent Generative AI programs. And, I want to highlight how language model outputs differ from the other mediums.
At a very high level, the goal of a watermark is to have some secret, which I think of as a secret key. Then, we need to maintain the expected language model functionality, so we have some function that take a prompt and produces a response. Finally, we need to be able to detect that the secret generated is “embedded” into the response. The following picture outlines the general structure for this type of watermark. This is generally referred to as a called a zero-bit watermark, since it is only indicating the presence of the watermark. One can natural extend this notion to multi-bit watermarks, but I won’t go over the differences specifically here.
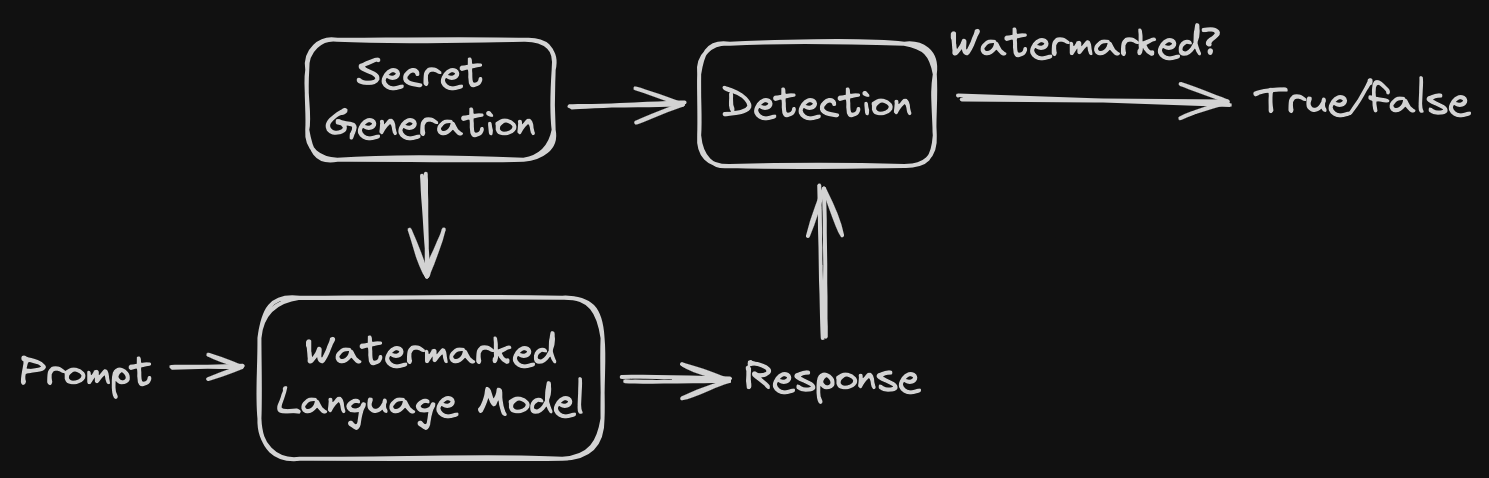
Notice that is is critical that detection does not know the prompt. There are works, such as Meteor, which focus on the setting where detection is given the prompt as well. However, for almost all other watermarking schemes, we assume that the prompt is unknown and only let detection have the response and secret as input.
The problem of watermarking digital content has been around for literally decades and there are many techniques to watermark content like images, videos, and audio. The key difference with watermarking language models is that the object we watermark is very small and very sensitive to change compared to these other digital objects. For example, by changing the least significant bits of image color values, one can modify an image to be imperceptibly different but encode a lot of information. This means that all of these large examples can be watermarked in a post-hoc way. It doesn’t matter how it was generated only that it is a large enough file to embed a signal to be detected later. And, this is the approach taken (at the time of writing) for watermarking these large Generative AI outputs.
In contrast, imagine watermarking a piece of already generated text. Any change to the words of the text is certainly going to be noticeable to a reader. There is no imperceptible difference that one can make just to english characters. The only real option is possibly to selectively rephrase parts of the text in a way that correlates with your secret, which has been tried. Unfortunately however this rephrasing is essentially using a different language model, which will significantly alter your final output distribution. On top of that, unless you rephrase very carefully, it may be very easy to remove your watermark.
We saw that watermarking language models comes with a host of challenges already. So, how useful is language model watermarking really? And, are there any good attributes we can hope for from a language model watermark?
Well those are both excellent questions! And, I’d say that they’re both open questions right now. However, the literature has already started to identify some attributes that make a watermark “good” and what the target properties are. In the next section, I’ll talk about what has been achieved in the literature along these axes of comparison. Unfortunately, it’s very hard to compare schemes directly, which was a large part of our recent paper’s goal. In this post, I’ll try to keep the language intuitive, but I would encourage anyone with a technical interest to read our paper or reach out to discuss more.
With the success of early ChatGPT models, there were many calls for new approaches to AI safety in 2022. The two original approaches were basically concurrently proposed by Scott Aaronson, who worked on the AI safety with OpenAI, and Kirchenbauer et al., who published a paper. These watermarks pioneered the space as being the first statistical watermarks (what I just call watermarks), meaning that they embed statistical correlations with the secret key into the response which can be detected later on.
However, the work of Christ et al. proposed a different approach to constructing the statistical watermarking language models. In particular, they came at the problem from a cryptographic perspective and introduced the notion of undetectability. This was a stronger guarantee on the quality of model outputs than the first two schemes. In particular, the scheme that they proposed has no detectable quality degradation of the model. And, following this set out cryptographic paradigm, Fairoze et al. built the first publicly-detectable watermark and Zamir constructed the first multi-bit undetectable watermark.
On the non-cryptographic side, Zhao et al. proved that a variant of the early Kirchenbauer scheme was robust to edits. And, Kuditipudi et al. provided the first distortion-free watermark that is also robust to edits and deletions.
More recently, there has been even more work following the cryptographic line. First with Christ and Gunn, who proposed a new primitive called pseudorandom error-correcting codes (PRCs) that can be used pretty directly to build watermarks with strong properties. This was quickly followed up by Golowich and Moitra, who built stronger PRCs and used them to construct even better watermarks.
Concurrently with Golowich and Moitra, Cohen et al. (my paper :)), provided the first black-box reduction and constructions using language model watermarks. Specifically, we build multi-bit watermarks from any zero-bit watermarking scheme. Then, we use our construction to build multi-user watermarks. In the processes, we unify prior works’ robustness into a common framework to compose and compare them. We also provide the first definitions over robustness in the fact of adaptive prompting and prove that the Christ et al. scheme satisfies this stronger notion of robustness.
And that pretty much brings us up to date. If there are other major works missing, please let me know! In the next section, I’ll give more details comparing these schemes.
It would be really nice if watermarks improved strictly on each other over time, but unfortunately most of the schemes that have been proposed are incomparable in at least one or more ways. I’ll try to explain briefly what some of these key differences are and how the schemes listed above differ. I’ll broadly discuss the existing schemes under the two categories “ml-style” and “crypto-style,” which broadly captures the central paradigms used to analyze the proposed watermarks.
The first builds statistical watermarks using frameworks that are more common to machine learning literature. This includes proving concrete bounds on Type 1 and Type 2 errors, a focus on preserving exact distributions, and detection that provides a number which indicates the probability of being watermarked. The latter category, takes a more cryptographic approach to statistical watermarks. The key indicator that a paper is using this paradigm is proving named properties, such as soundness and completeness. This line of work also often provides new definitions that enable additional functionality, relies on computational assumptions to build their watermarking, and requires longer response lengths to achieve these definitions.
Although these are practically oriented, it is difficult to precisely understand how they behave formally. For example, some schemes (e.g. ZALW23) have bounds on Type 1 error which do not provide meaningful asymptotic guarantees. Also, these schemes also have bespoke requirements for what constitutes a sufficiently long response to embed a watermark. However, each has been implemented and performs reasonably well in the experiments shown. However, many have free parameters which it is not clear how a user should set to achieve desired error trade-off.
The approach in these works definitely focuses on providing rigorous properties and definitions of the schemes. In particular, they have precise (but still bespoke) requirements for which responses are watermarked. And, they similarly prove that the desired properties hold with overwhelming probability under these conditions. Unfortunately, all rely on at least one cryptographic assumption which means that they are implicitly using some underlying cryptographic building blocks, which would introduce overhead in a real world implementation. And, especially for more recent proposals, this these assumptions are theoretical and seem very far from a practically realizable solution.
My work extends the theoretical line of “crypto-style” watermarks, because we believe this is the better direction for language model watermarking to head. As we deploy new technology, it is always important to balance the utility with the efficiency of what is deployed. However, considering the type of technology we are considering deploying, I lean on the side of caution and understand what the deployed watermark provides. As useful as it is to rapidly deploy some tools (like generative AI), we should be hesitant to deploy quick solutions to the accountability tools, which will hopefully serve as a backbone for AI safety. For these watermarking schemes, it is important that we errors on both sides as much as possible, until we fully understand how the accountability ecosystem will develop. Perhaps later on, we determine that having a high false positive detection for a faster watermark is not so bad, but for now, we should just focus on building the highest quality tool for the job.
That being said, I think some of the recent “crypto-style” work as taken the cryptographic open problems a bit too far. I personally do find it interesting to answer theoretical questions about the limits of pseudorandom error-correction codes. However, we should acknowledge that pushing these primitives with more and more wild cryptographic assumptions drives them further from practice. So, I would advise people to try and hold on to the precision of cryptography while simultaneously targeting the realistic and short-term deployment goals of language model watermarking.
Written: 2024-07 (Originally posted here.)
Last update: 2024-08 (minor edits)